
This article originally appeared over at https://www.distilled.net/resources/what-is-a-ranking-factor/. That URL 404s at the time of writing, hence the new location here.
Continue reading “What is a Ranking Factor?”Tag: SEO
Reading Between the Lines – Three Deeper Takeaways from John Mueller at BrightonSEO
This article originally appeared over at https://www.distilled.net/resources/john-mueller-at-brightonseo/. That URL 404s at the time of writing, hence the new location here.
Continue reading “Reading Between the Lines – Three Deeper Takeaways from John Mueller at BrightonSEO”5 Reasons Legacy Brands Struggle With SEO (and What to Do About Them)

A post bringing together some of my repeat experiences with larger clients.
DA is the Wrong Metric for Reporting on Link-Building

This article originally appeared over at https://www.distilled.net/resources/da-is-the-wrong-metric-for-reporting-on-link-building/. That URL 404s at the time of writing, hence the new location here.
Continue reading “DA is the Wrong Metric for Reporting on Link-Building”How to rank for head terms
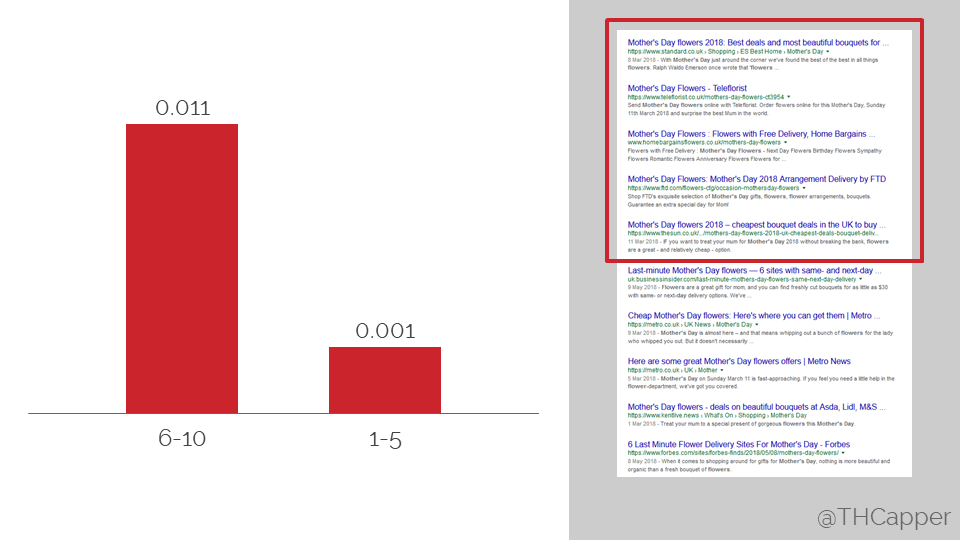
In effect, this is the blog of my SearchLove London 2018 deck – but should as such be quicker & easier to digest for people who weren’t there on the day.
The Two-Tiered SERP – SearchLove London 2018

A look at some ranking behaviour I’ve seen in the wild, and my working theory to explain it. I’m using “ranking factors” to describe the static metrics we’re all familiar with, and thinking about how dynamic feedback from SERPs might be feeding back into rankings where there’s enough data to do so.
Internal Linking for Mobile First
Something I’ve been thinking about for a while – what does internal linking best practice look like in a world with mobile first and (it turns out) “noindex,follow” URLs not being re-crawled? It’s easy enough for small sites, but this ought to be a major concern for any site with a 4+ figure page count.
Do you need local pages? – Whiteboard Friday

While I was in Seattle for MozCon, I had the chance to record a couple of videos for Whiteboard Friday – this was actually the one that I got out in a rush at the end, so hopefully I’ll be able to share the first one, too, in the fullness of time!
In the meantime, this is the 5-minute version of my MozCon talk, covering the meat of the analysis involved.
Local SEO Without Physical Premises

This is my presentation from MozCon 2018. The topic is local pages for national or international businesses – primarily how to figure out whether you need them, and some things not to do if you do need them. You can also watch a recording at – https://www.youtube.com/watch?v=rl_nazRbqY0.
Testing (no)followed links
Original text (24th January)
This page is explicitly “noindex,follow”.
Here are some links to pages that (at the time of writing) are not and have never been linked to anywhere else:
- Here’s a link to a page that is blocked in robots.txt.
- Here’s a nofollowed link.
- Here’s a perfectly normal link.
In about a month I’ll remove that robots.txt rule, and see if Google crawls the previously blocked page. If it does, that means that this page is still being treated as “noindex,follow”. If it doesn’t, and that remains the case for a reasonable period of time, that indicates that this page is being treated as “noindex,nofollow”.
I’m using robots.txt to do this because it means I don’t have to update this page to change what it (follow) links to – so if this mechanic described by John Mueller refreshes when the page is updated, that won’t invalidate my methodology.
Here’s a link to the Screaming Frog output as it currently stands.
Update (29th January)
Here’s the site: search result on January 29th (I forgot to check sooner):
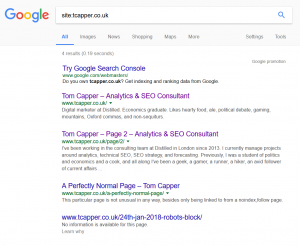
This is behaving as expected, with two of the pages linked to from here both found, but not the one that I’ve linked to with a “nofollow” attribute.
In addition, I decided to add this link, in case I need a 2nd robots.txt blocked URL to play with later:
- Here’s a second link to a page that is blocked in robots.txt (just in case).